

In our previous post, we delved into the fascinating world of local Retrieval-Augmented Generation (RAG) using Microsoft’s Phi-3 and the Semantic Kernel framework. I demonstrated how to build a basic Console App that showcases the capabilities of a local AI agent without relying on any online services. This journey was inspired by the need for data sovereignty and privacy, ensuring that sensitive information remains securely processed on-premises.
As we continue to push the boundaries of AI-first frameworks and small language models, it’s time to take our project to the next level. In this post, we will focus on adding persistent memories that can ingest and process various types of documents, including Word, PDF, Markdown, and JSON. By leveraging Kernel Memory, Semantic Kernel and Phi-3, we aim to create a robust and versatile solution that meets the productivity needs of modern enterprises, all within Microsoft .NET 🤖
Introducing Kernel Memory
Kernel Memory is a comprehensive AI Service which offers efficient indexing of datasets through custom continuous data hybrid pipelines with the support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering and custom semantic memory processing. This means that you can use Kernel Memory in your applications with any Large (or Small) Language Models.
The reason why I chose Kernel Memory over other options such as Chroma etc. is because it provides serverless memory support. Also, it supports a huge set of features which I have not seen in a single AI service that also has got a support for Semantic Kernel. Hence, this was my main motivation to choose Kernel Memory over others.
This is also very important for you to know that Kernel Memory is not like Semantic Memory (which was used in our previous post). As Kernel Memory’s team has done a great job in articulating those differences so I’ll link them here for you to read at your own convenience.
The approach
My approach was simple. As simple as just to replace the Semantic Memory with Kernel Memory and add some documents for ingestion. Therefore, I initially thought that I’d just bring in Kernel Memory service with 2 different types of documents and it will be a minimum code change, but I was wrong. Reason is that I wanted to ensure a complete offline capability for my agent and there was significant challenge which I encountered as I moved forward. Thankfully, I managed to address it and the demo works seamlessly well. All 100% RAG without localhost / internet.
Unexpected challenge
Whilst I was aware of a few challenges earlier due to the lack of good documentation (this is not uncommon when you’re dealing with the experimental / latest stuff), I came across some issues which took me a while to figure out what was going on internally. Nevertheless, all is well that ends well.
Kernel Memory has countless extensions but the Semantic Kernel one only supports ITextGenerationService as opposed to its own famous IChatCompletionService. This becomes tricky because all of the latest models (such as OnnxRuntime connectors) support IChatCompletionService as most of the latest models support ChatCompletions. Therefore, the extension methods refused to work with the existing IChatCompletionService service
The other challenge I found that it gets super slow and but as this isn’t in my control (because I am using Semantic Kernel’s OnnxRuntime connector) so I can’t enforce it to run CUDA or DirectML variant of the package. However, this was not a showstopper because all of this post is for research rather than a production ready solution.
How did I solve it?
When I figured out that it was not possible for me to use the existing extension methods for OnnxRuntime i.e. AddOnnxRuntimeGenAIChatCompletion, I decided to what everyone would do i.e. look out for a solution on GitHub but unfortunately, all I could find was the recently issue opened about it. This means there’s still no implementation available for the same. I thought rather than waiting for it, I should create a variant of AddOnnxRuntimeGenAIChatCompletionas AddOnnxRuntimeGenAITextCompletion
The other thing I also had to do is to specify the max_length as the default was just 300 and I couldn’t find a better way to override it, so I just setup as custom 3000 which you can change if you wish so.
Upon publishing my previous post, a lot of you asked me if I have pushed the sample to GitHub and I replied negative because I wanted to bring this capability. Now, I have and it is now a part of Generative AI repo.
Once these things are set, all I had to do was just to add these lines of code to our existing application which we created in our last post and that’s it, you’re good to go.
var config = new SemanticKernelConfig();
var memory = new KernelMemoryBuilder()
.WithSemanticKernelTextGenerationService(new OnnxRuntimeGenAITextCompletionService("phi-3", phi3modelPath), config, new GPT4Tokenizer())
.WithSemanticKernelTextEmbeddingGenerationService(embeddingGenerator, config, new GPT4Tokenizer())
.WithSimpleVectorDb()
.Build<MemoryServerless>();
var memoryPlugin = kernel.ImportPluginFromObject(new MemoryPlugin(memory, waitForIngestionToComplete: true), "memory");
await memory.ImportWebPageAsync("https://raw.githubusercontent.com/arafattehsin/ParkingGPT/main/README.md", documentId: "doc001");
await memory.ImportDocumentAsync($"Documents/HR Policy.docx");
As you can see, I am using types of documents here, one is marked down which is sourced from the internet while the other one is HR Policy.docx which is a local document. I am not storing it in any file-based system but if it is working well for in-memory scenarios, it will work fine for Vector DBs and others too.
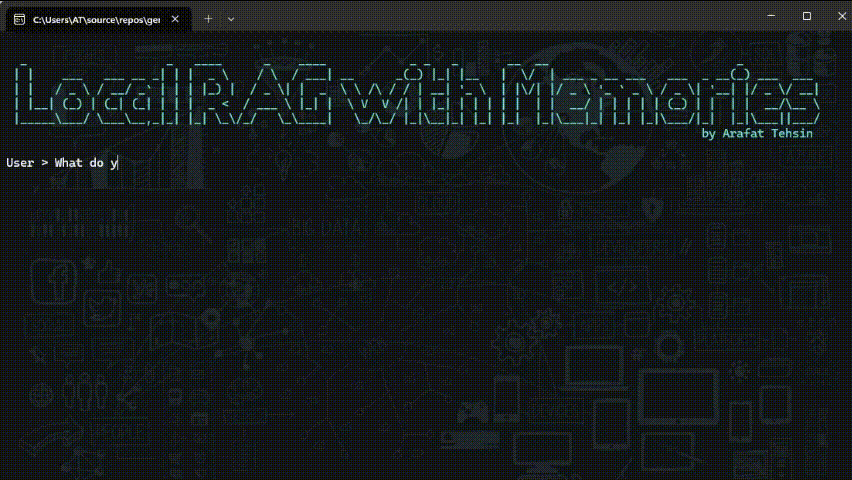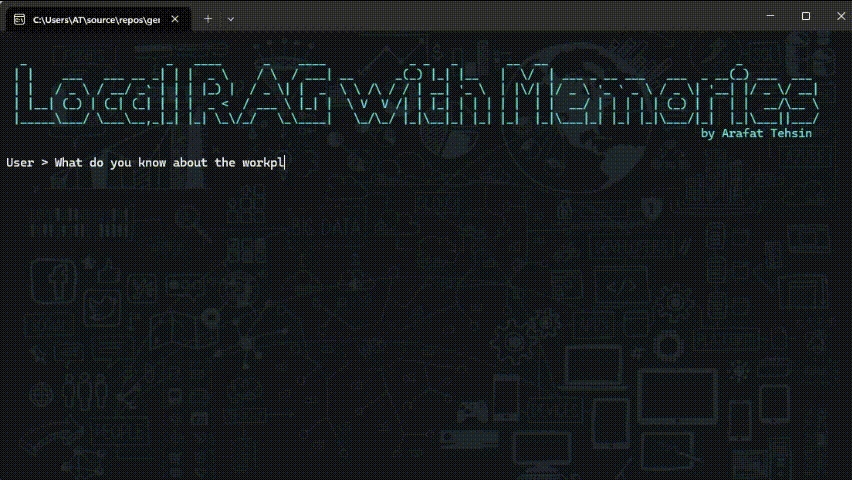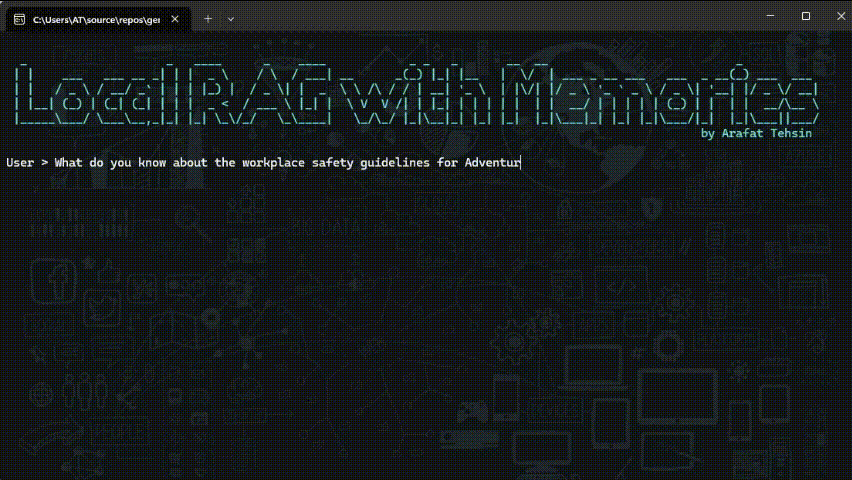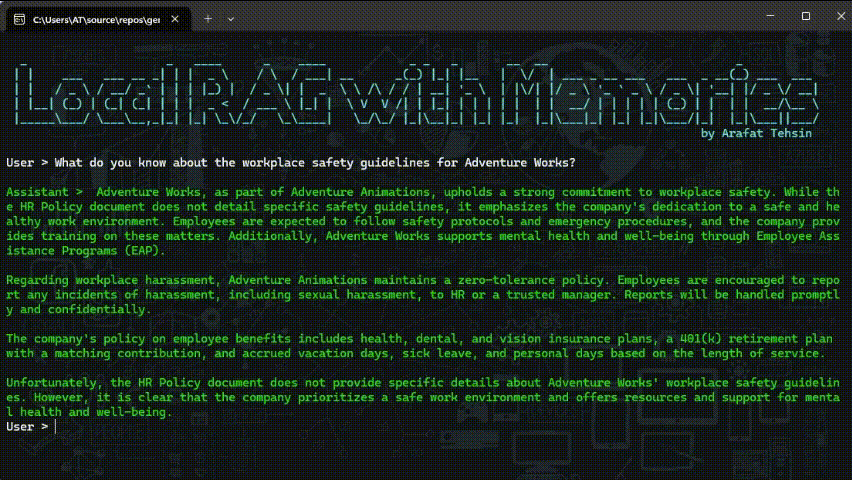
The above snapshot is already trimmed to give you an idea how it works but this is not as fast as it is shown here. It is pretty slow and I think this is where I believe that if teams do not improve to make it better, .NET developers may not be empowered as promised.
Integrating Kernel Memory with Semantic Kernel along with Phi-3 has given us an idea on how to use these models on the edge with persistent memory. Despite initial challenges, the successful implementation of offline capabilities and support for various document types demonstrates the potential of this approach. As we continue to explore and refine these technologies, the future of AI-first frameworks looks promising for enhancing productivity and ensuring data sovereignty.
Until next time.